
Quando si parla di traduzione automatica al giorno d’oggi, molti dei non addetti ai lavori pensano subito e volentieri a Google Translate. Si tratta, in definitiva, di un sistema semplice, dall’usabilità estrema, che restituisce traduzioni tutto sommato accettabili se si deve comprendere il contesto generale in un testo scritto in una lingua che non si conosce.
Traduzione automatica e reti neurali
Al prodotto di Google si possono affiancare quelli dei principali protagonisti del settore hi-tech, segnatamente Microsoft Translator, Facebook e il recente e ottimo DeepL Translator. Quest’ultimo, in particolare, è un servizio di traduzione lanciato nell’agosto 2017 da DeepL GmbH, una start-up sostenuta da Linguee, che fornisce anche il database linguistico. Il servizio supporta attualmente traduzioni tra le nove principali lingue europee. Le traduzioni di DeepL suonano un po’ più naturali di quelle degli altri servizi citati sopra. In particolare le traduzioni, rese a una velocità pari a quella dei concorrenti, sono considerati più precise e dense di sfumature. Oltre a quanto già affermato nella prima parte di questo post, come si riesce a misurare la qualità di un servizio di traduzione automatica rispetto al risultato che un essere umano si attende? Detto in maniera iper-semplificata, si effettua un confronto tra la traduzione resa dal sistema automatico e quella fatta da un essere umano. Più compiutamente, si utilizza il metodo comunemente definito BLEU (Bilingual Evaluation Understudy) illustrato da Papineni, Roukos, Ward e Zhu (2002) in “BLEU: a method for automatic evaluation of machine translation“. Il BLEU è un metodo per la valutazione automatica di un testo tradotto automaticamente. Un algoritmo misura la qualità del testo elaborato dalla macchina e la confronta con quella del testo tradotto dall’uomo. E’ stata una delle prime metriche ad ottenere un’alta correlazione con le valutazioni umane sulla qualità e rimane una tra le più popolari. I punteggi sono calcolati rispetto ai singoli segmenti tradotti – generalmente frasi – confrontandoli con un insieme di traduzioni di riferimento di buona qualità. Di questi punteggi viene poi calcolata la media rispetto all’intero corpus per ottenere una stima della qualità complessiva della traduzione. Ovviamente esistono anche dei limiti, come il fatto che le misurazioni non considerano l’intelligibilità o la correttezza grammaticale. Rico Sennrich, ricercatore del team di traduzione automatica dell’Università di Edimburgo e pioniere nella traduzione automatica neurale (NMT), ha dichiarato che BLEU è uno strumento essenziale per la ricerca e sviluppo della traduzione automatica, in particolare per il suo “feedback molto rapido sulla qualità di un sistema sperimentale”. Tuttavia, queste misurazioni si scontrano con il fatto che il linguaggio non è una scienza esatta. Il BLEU è “inefficiente nel misurare il valore grammaticale complessivo di una frase, assegnando solo una minima penalità per modifiche che appaiono insignificanti, ma in realtà cambiano completamente il significato di una traduzione”. Gli fa eco John Tinsley, CEO di Iconic Translation Machines, il quale ha detto chiaramente che il punteggio ottenuto tramite il BLEU “offre un’indicazione intuitiva più che assoluta (…)”. Qual è il motivo per il quale, almeno in tempi recenti, le traduzioni automatiche sembrano essere più “naturali” e meno rese da una macchina? La risposta sta nelle reti neurali. Le reti neurali sono un insieme di algoritmi, modellati liberamente secondo il cervello umano e progettati per riconoscere l’esistenza di modelli. Interpretano i dati sensoriali tramite quello che potremmo considerare una capacità di percezione grazie alla quale la macchina identifica, assegna un nome e raggruppa i dati non elaborati in base alla loro somiglianza rispetto ad altri dati di esempio. Cerco di spiegarmi meglio con un esempio: se conosciamo già cosa siano una forchetta in acciaio inox che ha 4 denti e una forchetta di plastica che ha 5 denti, cioè ne abbiamo registrato forma, colore, funzione, caratteristiche fisiche, dimensioni, ecc. e poi vediamo un oggetto di metallo dorato che ha approssimativamente la stessa forma e 3 denti, è altamente probabile che anche quell’oggetto sia una forchetta. Più sono i tipi di forchette che abbiamo visto e registrato, cioè maggiore è la nostra conoscenza di quel tipo di oggetto, più la nostra opinione sulla reale natura di un nuovo oggetto che osserviamo sarà attendibile. Le reti neurali sono anche in grado di estrarre caratteristiche di oggetti tramite algoritmi di classificazione separati ed essere quindi elementi di sistemi di apprendimento automatico più complessi. La forza di questi sistemi sta nella loro similitudine con il cervello umano, che si basa su apprendimento, memoria e correlazione di dati ed esperienze: è quello che si definisce apprendimento profondo, o deep learning. Naturalmente, le critiche alle reti neurali non mancano. In particolare, si rileva come:
- i modelli estratti o le strategie apprese dall’apprendimento profondo possano essere più superficiali di quanto non appaiano;
- che l’apprendimento profondo finora è limitato nella sua capacità di affrontare la struttura gerarchica;
- che le stesse apprendono complesse correlazioni tra caratteristiche di input e output senza alcuna rappresentazione intrinseca della causalità.
Per ulteriori approfondimenti è possibile consultare il paper di Gary Marcus dal titolo “Deep Learning: A Critical Appraisal” e il seguito nel post “In defense of skepticism about deep learning” (in inglese).
Traduzione neurale e traduzione automatica
Esistono dei campi in cui la traduzione automatica trova ormai amplissimo spazio, arrivando in alcuni casi a soppiantare interamente il traduttore umano. Mi riferisco, solo per citarne alcuni, a settori come:
- commercio elettronico;
- viaggi;
- gastronomia;
- blog.
Considerando il primo, vi sarà capitato di imbattervi in prodotti in vendita su Amazon la cui descrizione è incomprensibile. E dire che tra gli Amazon Web Services la traduzione neurale viene pubblicizzata come “accurata” e in grado di produrre “traduzioni rapide, di alta qualità e a costi contenuti”.
Ai fini della traduzione, il problema delle reti neurali sta nell’uso di un database “povero” dal quale attingere. Nel caso di Amazon, vista la sconfinata quantità di prodotti gestiti, non esiste un sufficiente numero di testi di qualità sui quali apprendere e la traduzione automatica fa quel (poco) che può.
Vediamo come funzionano le reti neurali. A differenza della traduzione automatica pura, che si appoggia a un database cercando la corrispondenza al 100%, ovvero a percentuali inferiori (fuzzy matches) che rappresentano una corrispondenza simile, ma non identica tra il segmento sorgente e quello presente nella memoria di traduzione.
Per contro, il concetto di rete neurale non è di per sé complicato e riflette le funzioni delle reti neurali degli organismi viventi.
La rete neurale in sé non è un algoritmo, ma piuttosto un contenitore di molti algoritmi diversi di apprendimento automatico che serve a farli lavorare insieme per elaborare dati complessi. Una rete neurale si basa su un insieme di unità o nodi collegati, chiamati neuroni artificiali, una sorta di modello dei neuroni in un cervello biologico. Analogamente, ogni connessione può trasmettere un segnale da un neurone artificiale ad un altro. Un neurone artificiale che riceve un segnale può elaborarlo e quindi segnalare ulteriori neuroni artificiali ad esso collegati.
Tuttavia, il peso e la prevalenza di ciascuno dei neuroni e delle sinapsi artificiali complicano il quadro. Stiamo parlando di un gruppo di collegamenti che lavorano insieme senza che a nessuno sia assegnato un compito specifico. Per comprendere come sfruttare al meglio le reti neurali, quindi, bisogna considerare che il processo consiste nello stabilire un insieme di parametri i quali, quando combinati, sono in grado di garantire un apprendimento profondo e adeguare nel tempo le prestazioni.
Coloro i quali si occupano di reti neurali devono risolvere un problema di non poco conto, dal momento che l’attenzione non deve concentrarsi sull’analisi dei parametri che devono essere collegati tra loro (es. frase in lingua originale — frase in lingua di destinazione), ma sul come creare una combinazione tra i diversi parametri che generano la risposta (se A non corrisponde a B, allora potrebbe corrispondere a C).
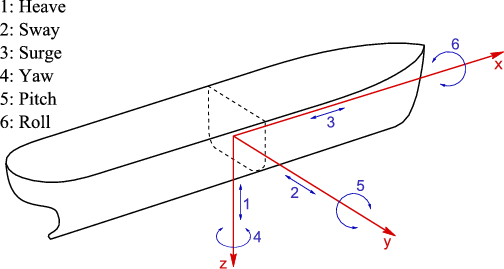
Essi studiano, cioè, come collegare i concetti e far sì che una macchina esegua processi di associazione alla stessa velocità degli esseri viventi. Per fare questo – e qui sta il passaggio che ancora rende “lento” il processo – si devono ricercare i vantaggi del cervello quando associa concetti che un computer ha difficoltà a identificare. In senso figurato, gli scienziati provano una forte invidia nei confronti dei pipistrelli, ad esempio, i quali godono dell’impareggiabile qualità di riuscire a determinare con assoluta precisione la velocità relativa e le dimensioni delle prede e la posizione degli oggetti intorno ad esse. Si tratta di un piccolo miracolo in termini di calcolo iterativo, anche perché vi sono i cosiddetti sei gradi di libertà: le tre coordinate spaziali x,y,z della posizione della preda cambiano e vengono ricalcolate istante dopo istante, come anche i movimenti di beccheggio, rollio e imbardata.
In termini di intelligenza artificiale, si parla di creazione o presa di coscienza, o auto-consapevolezza della macchina. Si è visto, in sostanza, che una macchina ha molta più difficoltà di un essere vivente genericamente inteso a capire di cosa è capace e a riutilizzare le esperienze fatte. Il problema potrà essere superato nel momento in cui si avrà a disposizione una maggiore capacità di calcolo e di storage retrieval neurale.
Come cambia il lavoro del traduttore?
Per rispondere a questa domanda, preferisco citare l’articolo “TRADUTTORI UMANI O TRADUZIONE AUTOMATICA NEURALE?” di Gabriele Galati e Hellmut Riediger, laddove dicono (grassetto mio):
Intanto possiamo considerare la traduzione neurale una nuova tappa di una rivoluzione, avviata già da tempo dalla traduzione statistica. (…)
Da anni, i sistemi di traduzione automatica, integrati ormai anche nei sistemi di traduzione assistita impiegati dai traduttori nella loro pratica professionale (…) sono già largamente usati da fornitori di servizi linguistici e servizi di traduzione di istituzioni pubbliche e private.
Già nel 2009 quasi il 50% degli operatori della traduzione (servizi linguistici e traduttori) dichiarava di far uso più o meno frequentemente di sistemi di traduzione automatica.
Nel 2014 il valore di mercato della traduzione automatica è stato stimato pari a 250 milioni di dollari e il trend di crescita appare irreversibile (…). Secondo un recente studio di Lommel e DePalma (2016), le aziende tendono ad aumentare gli investimenti nella cosiddetta post-editing Machine Translation (PEMT) cioè l’uso della traduzione automatica per produrre una prima bozza della traduzione da correggere successivamente, ed entro il 2019 tradurranno o pre-tradurranno con la traduzione automatica il 59% dei loro contenuti. Lommel e DiPalma prevedono, tra il 2016 e il 2019, un raddoppio del numero complessivo di parole tradotte con un raddoppio della parte tradotta in automatico (senza o con Post-editing), ma senza che questo significhi un calo della componente di traduzione umana, che, anzi, aumenterà anch’essa.
Il problema dunque non è tanto l’espulsione degli umani dal mondo della traduzione, semmai, quanto il livello delle tariffe che vengono pagate. Come in tutti i settori, si contrae il valore economico del lavoro umano. Grazie alla concorrenza al ribasso favorita dalla globalizzazione e da internet c’è sempre qualcuno che offre merci e servizi a prezzi inferiori, anche di traduzione. (…)
L’automatizzazione della traduzione, di qualsiasi genere, renderà superflui i traduttori? Probabilmente no, o quanto meno non nel futuro prossimo. Tuttavia si svilupperanno nuove modalità e nuove prassi nella comunicazione interlinguistica che richiederanno nuove conoscenze e competenze che occorre apprendere…rapidamente. Proviamo ad elencarne qualcuna.
Ovviamente i traduttori dovranno possedere spiccate competenze tecnologiche. Dovranno possedere cultura, capacità di scrittura e approfondite conoscenze linguistiche e settoriali per essere in grado di valutare difficoltà e qualità dei testi. Dovranno essere in grado di gestire grandi quantità di testi in tempi circoscritti. Dovranno saper valutare se conviene tradurre automaticamente, valutare la quantità di post-editing, saper sottoporre un testo a pre-editing prima della sua traduzione, saper scrivere testi traducibili (scrittura controllata), saper addestrare i sistemi di traduzione automatica o adattarli alle esigenze particolari. I traduttori diventeranno sempre più gestori di progetti di traduzione o di redazione multilingue. Un po’ redattori, editor, project manager, ma soprattutto sempre più revisori. Prima e dopo la stesura della traduzione, svolta dalla macchina. (…) Già da qualche lustro, scrivere significa interagire con una varietà di tecnologie e memorie digitali (dizionari, glossari, banche dati, corpora, motori di ricerca ecc.). Poiché il principale effetto della rivoluzione tecnologica è stato l’enorme aumento delle nostre possibilità di memorizzare i dati, una parte sempre più cospicua dell’attività del traduttore consiste nella ricerca delle fonti (memorie) adatte prima della stesura e in varie forme di traduzione intralinguistica o adattamento (revisione, correzione di segmenti, post-editing ecc.) dopo la stesura.
Pertanto da anni ormai il lavoro del traduttore consiste in larga misura nell’assemblare (copiare e incollare) frammenti recuperati da un qualche tipo di memoria digitale: porzioni di testo, espressioni o termini recuperati da propri precedenti lavori, dai risultati dei motori di ricerca, da dizionari elettronici, glossari, da banche dati terminologiche, da corpora paralleli reperiti in rete, da bitext, da memorie di traduzione oppure, appunto, da pre-traduzioni fornite da sistemi di traduzione automatica.
Conclusioni
L’importanza della traduzione automatica mediante reti neurali è crescente e inarrestabile in virtù di due fattori economici e non tecnici: velocità e quantità.
La velocità può dipendere da differenti fattori, tra cui la combinazione linguistica, le dimensioni del motore di traduzione e il formato del documento. Se però si considera che un motore addestrato può tradurre fino a un miliardo di parole al giorno in maniera coerente con se stesso, è chiaro che nessun traduttore o gruppo di traduttori è in grado di competere con queste prestazioni. Ecco perché i traduttori che ricorrono alla traduzione automatica possono contare su vantaggi competitivi fin dal primo istante.
Ecco che le aziende – non le piccole e medie imprese, ma le grandi e grandissime, come Coca Cola, Amazon, Facebook – devono localizzare enormi quantità di contenuti con risorse limitate. Pensate a quanto sia vasta la quantità di testi da tradurre in termini di post e commenti sulle principali piattaforme (Facebook, Twitter, LinkedIn): si potrebbe mai pensare di assegnare tale compito a eserciti di traduttori umani? La traduzione automatica diventa, a quel punto, l’unica risorsa con cui quegli attori commerciali possono permettersi di localizzare contenuti che non sarebbero altrimenti fruibili.
Come ricorda Diego Cresceri di Creative Words, nel post ‘‘A che ora è la fine della traduzione umana’ “(…) “in molti casi, la machine translation non è un prodotto sostitutivo quanto un servizio completamente diverso, destinato a contenuti di tipo diverso“.